Introduction
The field of Natural Language Processing (NLP) has witnessed a paradigm shift with the advent of Transformer architectures. Introduced by Vaswani et al. in 2017, Transformers have revolutionized how machines understand and generate human language. They have become the backbone of numerous state-of-the-art models like BERT, GPT-3, and T5, powering applications from machine translation to text summarization.
In this comprehensive guide, we’ll delve deep into the world of Transformers. We’ll explore their architecture, understand the underlying mechanisms, and provide a step-by-step implementation using Python and PyTorch. Whether you’re a seasoned AI practitioner or a curious enthusiast, this article aims to enhance your understanding and equip you with practical skills to implement Transformers in your projects.
1. The Evolution of NLP Models
Natural Language Processing has evolved through various stages:
- Statistical Methods: Early NLP relied on statistical models like n-grams and Hidden Markov Models.
- Neural Networks: The introduction of neural networks brought models like RNNs and LSTMs, which could capture sequential dependencies.
- Attention Mechanisms: Enhancements to RNNs with attention mechanisms allowed models to focus on specific parts of the input sequence.
- Transformers: Eliminating recurrence altogether, Transformers use attention mechanisms to process sequences in parallel, achieving superior performance.
2. What Makes Transformers Unique
Transformers stand out due to:
- Parallelization: Unlike RNNs, Transformers process entire sequences simultaneously, significantly reducing training time.
- Scalability: They handle long-range dependencies better, making them suitable for longer texts.
- Versatility: Transformers have been adapted for various tasks beyond NLP, including computer vision and speech recognition.
3. The Attention Mechanism Explained
At the heart of Transformers is the attention mechanism, which allows models to weigh the importance of different parts of the input data.
Self-Attention: It enables the model to consider the entire sequence when processing each element. For example, in a sentence, understanding the context of a word may depend on all other words.
Scaled Dot-Product Attention: The calculation involves queries (Q), keys (K), and values (V):
Attention(Q,K,V)=softmax(QKTdk)V\text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right) VAttention(Q,K,V)=softmax(dkQKT)V
Where dkd_kdk is the dimension of the key vectors.
Multi-Head Attention: Instead of performing a single attention function, the model uses multiple heads to capture different aspects of the relationships.
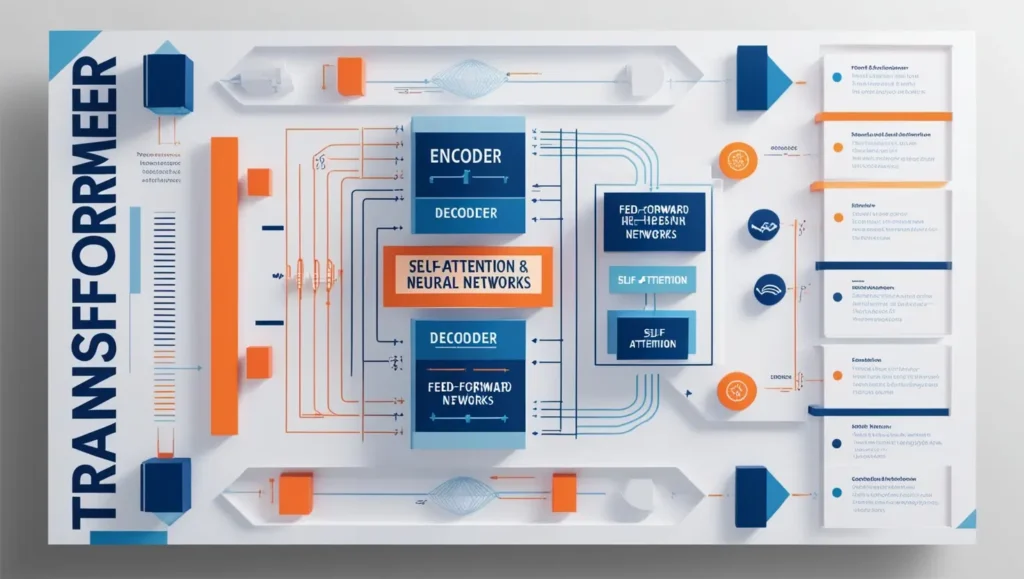
4. Deep Dive into Transformer Architecture
The Transformer architecture comprises an Encoder and a Decoder, each made of stacked layers.
4.1 Encoder and Decoder Structures
- Encoder: Processes the input sequence and generates continuous representations.
- Decoder: Uses the encoder’s output to generate the target sequence.
Each layer in the encoder and decoder consists of sub-layers:
- Multi-head attention mechanisms.
- Position-wise feed-forward networks.
4.2 Multi-Head Attention
Multi-head attention allows the model to focus on different positions. Each head learns to attend to different parts of the input.
Implementation:
- Split the input into multiple heads.
- Perform scaled dot-product attention in each head.
- Concatenate the outputs and project them back to the original dimension.
4.3 Positional Encoding
Since Transformers lack inherent sequential order, positional encoding injects information about the position of each token.
Formula:
For position pospospos and dimension iii:
PE(pos,2i)=sin(pos100002i/dmodel)PE_{(pos, 2i)} = \sin\left( \frac{pos}{10000^{2i/d_{\text{model}}}} \right)PE(pos,2i)=sin(100002i/dmodelpos) PE(pos,2i+1)=cos(pos100002i/dmodel)PE_{(pos, 2i+1)} = \cos\left( \frac{pos}{10000^{2i/d_{\text{model}}}} \right)PE(pos,2i+1)=cos(100002i/dmodelpos)
4.4 Feed-Forward Networks
These are simple fully connected layers applied to each position separately and identically.
Structure:
- Linear layer with ReLU activation.
- Another linear layer projecting back to the model dimension.
4.5 Layer Normalization and Residual Connections
- Residual Connections: Help in training deep networks by adding the input of a layer to its output.
- Layer Normalization: Normalizes the outputs of the sub-layers to stabilize and accelerate training.
5. Implementing a Transformer from Scratch
5.1 Setting Up the Environment
Requirements:
- Python 3.6+
- PyTorch
- TorchText
- SpaCy (for tokenization)
Installation:
bash
pip install torch torchtext spacy
python -m spacy download en_core_web_sm
python -m spacy download de_core_news_sm
5.2 Preparing the Dataset
We’ll use the Multi30k dataset for English-German translation.
Loading the Data:
python
from torchtext.data import Field, BucketIterator
from torchtext.datasets import Multi30k
import spacy
spacy_eng = spacy.load("en_core_web_sm")
spacy_ger = spacy.load("de_core_news_sm")
def tokenize_eng(text):
return [tok.text.lower() for tok in spacy_eng.tokenizer(text)]
def tokenize_ger(text):
return [tok.text.lower() for tok in spacy_ger.tokenizer(text)]
SRC = Field(tokenize=tokenize_ger, init_token="", eos_token="", lower=True)
TRG = Field(tokenize=tokenize_eng, init_token="", eos_token="", lower=True)
train_data, valid_data, test_data = Multi30k.splits(exts=('.de', '.en'), fields=(SRC, TRG))
Building Vocabulary:
pythonSRC.build_vocab(train_data, min_freq=2)
TRG.build_vocab(train_data, min_freq=2)
Creating Data Loaders:
python
from torch.utils.data import DataLoader
BATCH_SIZE = 32
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
device=device
)
5.3 Building the Model Components
Defining the Multi-Head Attention Layer:
python
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
assert d_model % n_heads == 0
self.d_k = d_model // n_heads
self.h = n_heads
self.q_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.out = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
bs = q.size(0)
# Perform linear operation and split into h heads
q = self.q_linear(q).view(bs, -1, self.h, self.d_k)
k = self.k_linear(k).view(bs, -1, self.h, self.d_k)
v = self.v_linear(v).view(bs, -1, self.h, self.d_k)
# Transpose to get dimensions bs * h * seq_len * d_k
q, k, v = [x.transpose(1, 2) for x in (q, k, v)]
# Calculate attention
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn = torch.softmax(scores, dim=-1)
output = torch.matmul(attn, v)
# Concatenate heads and put through final linear layer
output = output.transpose(1, 2).contiguous().view(bs, -1, self.d_model)
output = self.out(output)
return output
Defining the Encoder Layer:
python
class EncoderLayer(nn.Module):
def __init__(self, d_model, n_heads, ff_hidden, dropout):
super().__init__()
self.attention = MultiHeadAttention(d_model, n_heads)
self.norm1 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.ff = nn.Sequential(
nn.Linear(d_model, ff_hidden),
nn.ReLU(),
nn.Linear(ff_hidden, d_model)
)
self.norm2 = nn.LayerNorm(d_model)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask):
x2 = self.attention(x, x, x, mask)
x = self.norm1(x + self.dropout1(x2))
x2 = self.ff(x)
x = self.norm2(x + self.dropout2(x2))
return x
Building the Full Encoder:
python
class Encoder(nn.Module):
def __init__(self, vocab_size, d_model, n_layers, n_heads, ff_hidden, dropout, max_length=100):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_embedding = nn.Embedding(max_length, d_model)
self.layers = nn.ModuleList(
[EncoderLayer(d_model, n_heads, ff_hidden, dropout) for _ in range(n_layers)]
)
self.dropout = nn.Dropout(dropout)
def forward(self, src, mask):
seq_length = src.size(1)
positions = torch.arange(0, seq_length).unsqueeze(0).repeat(src.size(0), 1).to(device)
x = self.dropout(self.embedding(src) + self.pos_embedding(positions))
for layer in self.layers:
x = layer(x, mask)
return x
Similarly, Define the Decoder and Transformer Model
Due to space constraints, the full code for the decoder and the transformer model is omitted but follows a similar structure.
5.4 Training the Transformer
Setting Hyperparameters:
python
D_MODEL = 512
N_LAYERS = 6
N_HEADS = 8
FF_HIDDEN = 2048
DROPOUT = 0.1
Initializing the Model:
python
model = Transformer(
src_vocab_size=len(SRC.vocab),
trg_vocab_size=len(TRG.vocab),
d_model=D_MODEL,
n_layers=N_LAYERS,
n_heads=N_HEADS,
ff_hidden=FF_HIDDEN,
dropout=DROPOUT
).to(device)
Defining Loss and Optimizer:
python
criterion = nn.CrossEntropyLoss(ignore_index=TRG.vocab.stoi["<pad>"])
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
Training Loop:
python
EPOCHS = 10
for epoch in range(EPOCHS):
model.train()
epoch_loss = 0
for batch in train_iterator:
src = batch.src.to(device)
trg = batch.trg.to(device)
optimizer.zero_grad()
output = model(src, trg[:,:-1])
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
trg = trg[:,1:].contiguous().view(-1)
loss = criterion(output, trg)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(train_iterator)
print(f"Epoch {epoch+1}/{EPOCHS}, Loss: {avg_loss:.4f}")
5.5 Evaluating Performance
Validation Loop:
python
model.eval()
with torch.no_grad():
val_loss = 0
for batch in valid_iterator:
src = batch.src.to(device)
trg = batch.trg.to(device)
output = model(src, trg[:,:-1])
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
trg = trg[:,1:].contiguous().view(-1)
loss = criterion(output, trg)
val_loss += loss.item()
avg_val_loss = val_loss / len(valid_iterator)
print(f"Validation Loss: {avg_val_loss:.4f}")
Testing the Model:
Generate translations for test sentences and compare them with reference translations.
6. Applications of Transformers in NLP
Transformers have broad applications:
- Machine Translation: Models like Transformer and MarianMT offer high-quality translations.
- Text Summarization: BART and T5 models summarize long texts effectively.
- Question Answering: BERT and RoBERTa excel in understanding context to answer questions accurately.
- Language Generation: GPT-3 generates coherent and contextually relevant text, powering chatbots and content creation tools.
- Sentiment Analysis: Transformers capture nuanced sentiments in text data, aiding in customer feedback analysis.
For more practical examples of NLP models in action, check out our Python-based guide to AI in finance, which shows how to apply intelligent algorithms to real-world datasets.
7. Challenges and Future Directions
While Transformers are powerful, they face challenges:
- Computational Resources: Training large models requires significant computational power and memory.
- Data Requirements: They need vast amounts of data to perform well.
- Interpretability: Understanding the decision-making process of Transformers is complex.
- Bias and Fairness: Models can inadvertently learn and amplify biases present in the training data.
Future Research Areas:
- Efficient Transformers: Developing architectures that reduce resource consumption (e.g., Reformer, Linformer).
- Multimodal Learning: Integrating text with images, audio, and video.
- Continual Learning: Enabling models to learn incrementally without forgetting previous knowledge.
- Explainability: Creating methods to interpret and visualize attention mechanisms for better transparency.
8. Conclusion
Transformers have undeniably transformed NLP, offering unprecedented capabilities in understanding and generating human language. By mastering their architecture and implementation, you’re equipped to contribute to cutting-edge developments in AI.
Whether you’re building translation systems, chatbots, or content generators, understanding Transformers is invaluable. As the field progresses, staying updated with the latest research and refining your skills will keep you at the forefront of AI innovation.
9. References
- Vaswani, A., Shazeer, N., Parmar, N., et al. (2017). Attention is All You Need. Advances in Neural Information Processing Systems, 5998-6008.
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- Brown, T., Mann, B., Ryder, N., et al. (2020). Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165.
- Wolf, T., Debut, L., Sanh, V., et al. (2020). Transformers: State-of-the-Art Natural Language Processing. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 38-45.
About the Author
TechFlareAI is dedicated to bringing you the latest insights and tutorials in artificial intelligence. Our mission is to ignite innovation by making complex AI concepts accessible to everyone.
Join the Conversation
Have questions or insights about Transformers? Share your thoughts in the comments below or join our community forum to discuss with like-minded enthusiasts!
Stay Tuned
Subscribe to our newsletter to receive daily updates on AI trends, tutorials, and innovative projects straight to your inbox.
If you’re just starting with AI and want to understand the foundations, we recommend reading how to start your AI learning journey.
Want to test out some NLP tools yourself? Explore our list of top 5 free AI tools you should know about and start experimenting today
5 thoughts on “Understanding and Implementing Transformers in Natural Language Processing: A Comprehensive Guide”