Introduction
Understanding how neural networks function internally is crucial to appreciating their capabilities. Neural networks are complex structures, composed of layers of artificial neurons that interact through weights and biases. This architecture allows them to process data, identify patterns, and make predictions. In this article, we will explore the internal structure of neural networks in depth, covering key concepts such as layers, activation functions, weights, and biases, and examining how these elements work together to enable learning and decision-making.
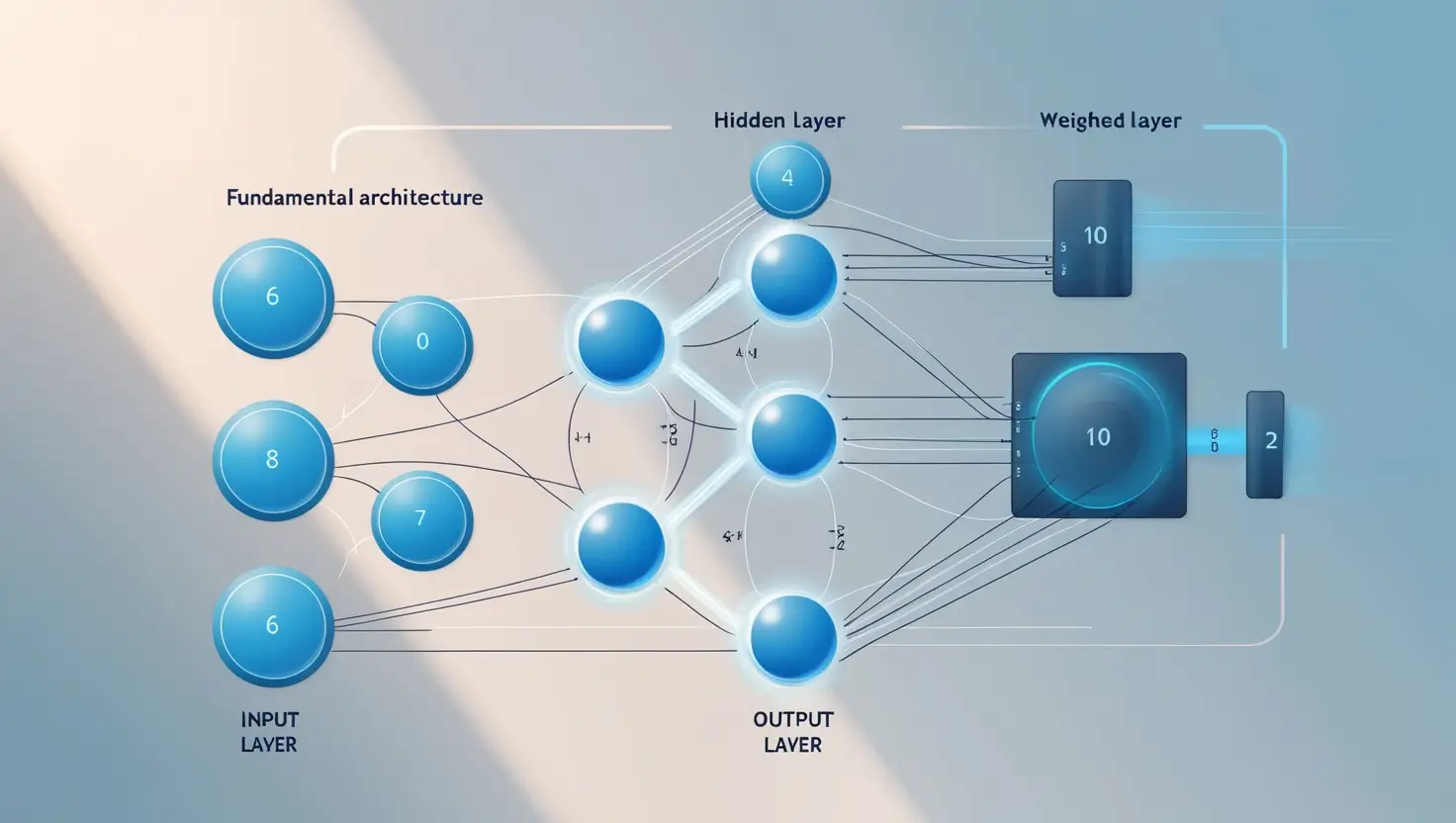
The Basic Structure of a Neural Network
A neural network’s structure is inspired by the human brain, which consists of a vast network of neurons that process and transmit information. In an artificial neural network, this structure is represented by layers of nodes (or neurons) that are connected by weighted links. Each layer performs specific functions in the process of data transformation.
Types of Layers in a Neural Network
- Input Layer: This is the first layer in the network, responsible for receiving raw data. Each node in the input layer represents a specific feature of the input data, such as a pixel in an image or a word in a sentence.
- Hidden Layers: Located between the input and output layers, hidden layers process data by performing complex transformations. Each neuron in a hidden layer receives input from the previous layer, applies specific calculations, and passes the output to the next layer. The more hidden layers a network has, the deeper it is, and the more complex patterns it can learn.
- Output Layer: The final layer in the network, the output layer provides the network’s predictions. For example, in a classification task, the output layer might label the input data as a specific category, such as “cat” or “dog.”
In practice, data flows from the input layer, through one or more hidden layers, and finally to the output layer. Each layer applies transformations to the data, which collectively allow the network to learn and make accurate predictions.
Deep Neural Networks (DNNs)
When a neural network has multiple hidden layers, it is known as a deep neural network (DNN). DNNs can learn complex representations of data and are the basis of “deep learning.” They are used in advanced applications such as image and speech recognition, natural language processing, and autonomous driving.
- Example: In a DNN used for image recognition, the initial hidden layers might detect simple features like edges or colors, while deeper layers identify more complex features, such as shapes or objects. By the time data reaches the final layer, the network has learned a detailed representation of the image, allowing it to classify it accurately.
To see how these deep models are applied in real-world use cases, check out our introduction to neural networks and their applications.
Activation Functions: Bringing Non-Linearity to Neural Networks
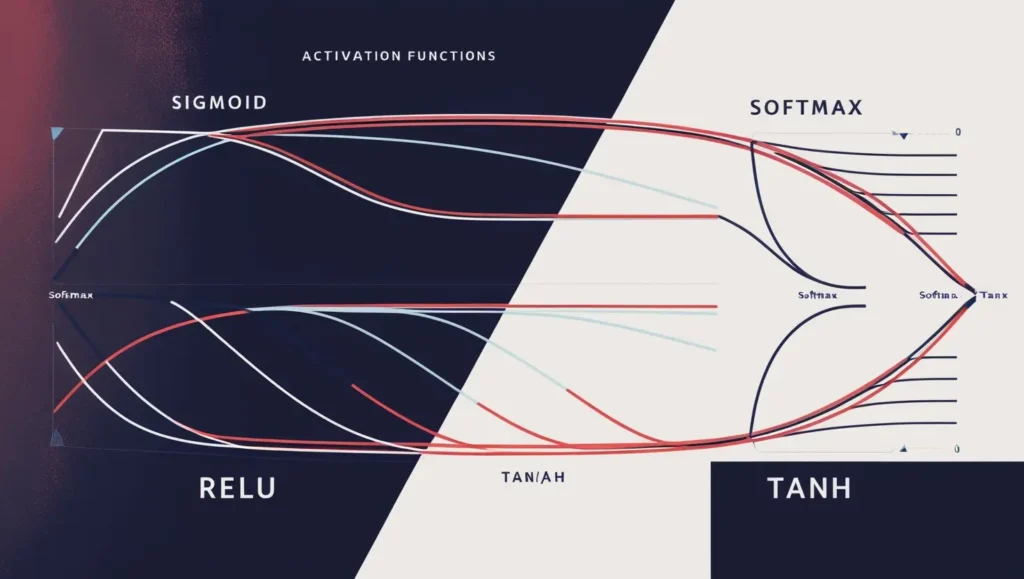
An activation function is a critical component of each neuron in a neural network. It determines whether the neuron should “activate” (or fire) based on the input it receives. Activation functions introduce non-linearity, allowing neural networks to model complex relationships in data.
Types of Activation Functions
- Sigmoid Function: The sigmoid function maps any input into a probability between 0 and 1. It is commonly used in binary classification tasks where the output needs to represent a probability.
- Formula: σ(x)=11+e−x\sigma(x) = \frac{1}{1 + e^{-x}}σ(x)=1+e−x1
- Use Case: Often used in the output layer of binary classifiers.
- ReLU (Rectified Linear Unit): ReLU is the most commonly used activation function in hidden layers. It outputs the input directly if it’s positive; otherwise, it returns zero. ReLU helps networks learn faster by mitigating the vanishing gradient problem.
- Formula: f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x)
- Use Case: Widely used in hidden layers of deep networks due to its simplicity and efficiency.
- Softmax Function: Softmax is typically used in the output layer for multi-class classification tasks. It converts the output scores into probabilities, with the highest probability indicating the predicted class.
- Formula: softmax(xi)=exi∑jexj\text{softmax}(x_i) = \frac{e^{x_i}}{\sum_{j} e^{x_j}}softmax(xi)=∑jexjexi
- Use Case: Common in the output layer of neural networks with multiple classes.
- Tanh (Hyperbolic Tangent): Similar to sigmoid, the Tanh function scales inputs between -1 and 1. This helps center the data, making learning faster in some cases.
- Formula: tanh(x)=21+e−2x−1\tanh(x) = \frac{2}{1 + e^{-2x}} – 1tanh(x)=1+e−2×2−1
- Use Case: Often used in hidden layers for networks dealing with sequential data, such as RNNs.
Each activation function has unique properties and is chosen based on the specific needs of the neural network. The choice of activation function can significantly impact the network’s ability to learn complex patterns and make accurate predictions.
Want to understand how modern NLP tools use activation layers? Read our breakdown on Transformers in Natural Language Processing.
Understanding Weights and Biases
Weights and biases are two crucial parameters that govern how a neural network learns. They influence how data is transformed as it passes through the network, ultimately determining the network’s accuracy and effectiveness.
Weights
Weights represent the strength of the connection between two neurons. When data passes from one neuron to the next, it is multiplied by a weight. Higher weights indicate a stronger influence, while lower weights signify a weaker connection.
- Adjusting Weights: During training, weights are adjusted to reduce errors in the network’s predictions. This process is called backpropagation and is crucial for fine-tuning the network’s performance.
- Example: Suppose a neural network is trained to recognize handwritten digits. Each pixel in an image of a digit has an associated weight. By adjusting these weights, the network learns to focus on important features (like edges and curves) and ignore irrelevant information (such as noise).
Biases
Biases are additional parameters added to the weighted input before passing it through the activation function. Biases help shift the activation function, allowing the network to fit the data more accurately.
- Role of Bias: Bias enables neurons to have flexibility in their activation. Even if all input values are zero, the presence of a bias allows the neuron to activate based on its bias value.
- Example: In a network classifying images as “cat” or “dog,” biases allow each neuron to make slight adjustments, ensuring the network can accurately classify images even when they vary slightly from the training data.
By adjusting weights and biases, a neural network can learn from data and improve its performance over time. The network continuously updates these parameters during training, gradually reducing its prediction errors and enhancing accuracy.
The Process of Forward and Backward Propagation
To understand how weights and biases are adjusted, let’s examine the two main processes involved in training a neural network: forward propagation and backward propagation.
Forward Propagation
In forward propagation, input data is passed through the network layer by layer, with each neuron calculating an output based on its input, weight, bias, and activation function. The data moves from the input layer to the output layer, where the network produces a final prediction.
- Example: In a network identifying handwritten digits, forward propagation involves processing the pixel values through the network’s layers, with each layer extracting increasingly complex features. By the output layer, the network assigns a probability to each possible digit.
Backward Propagation
Backward propagation, or backpropagation, is the process by which the network learns from its errors. After the network makes a prediction, it compares it to the actual outcome and calculates the error (loss). This error is then propagated backward through the network, adjusting weights and biases to minimize future errors.
- Gradient Descent: Backpropagation uses an optimization algorithm called gradient descent. Gradient descent adjusts weights and biases by following the direction of steepest descent on the loss function. Over time, this process reduces the network’s prediction error, enhancing its accuracy.
Looking to build and train your own network? Follow our step-by-step Python guide for building a neural network
Why Weights, Biases, and Activation Functions Matter
The combination of weights, biases, and activation functions enables neural networks to model complex, non-linear relationships in data. By adjusting these parameters, neural networks can learn intricate patterns and make accurate predictions across a wide range of applications.
- Weights and biases allow the network to adjust its understanding of the input data, highlighting important features while ignoring irrelevant details.
- Activation functions introduce non-linearity, which is essential for solving complex problems that cannot be addressed with simple linear models.
Together, these components enable neural networks to process data, learn from it, and make decisions that can adapt to diverse tasks, from image classification to natural language processing.
If you’re new to AI, begin your journey with our complete beginner’s guide to learning AI, perfect for non-tech backgrounds.
Conclusion
The internal structure of neural networks, including their layers, weights, biases, and activation functions, is fundamental to their ability to learn and make predictions. By understanding these elements, we can appreciate how neural networks mimic human intelligence, processing data to uncover patterns and insights. As the field of AI continues to evolve, so too will the complexity and sophistication of neural networks, unlocking even more potential applications in the future.
1 thought on “How Neural Networks Work: Activation Functions, Weights & Structure”